Data Infrastructure Services, Part 2: Getting Data into the Warehouse
That data warehouse isn't too useful until we fill it up with stuff. One of the key sources of data is your transactional database. We happen to be using a tool called Xplenty to fill this role for us.
Xplenty lets you create jobs called "packages". Choose from a number of sources
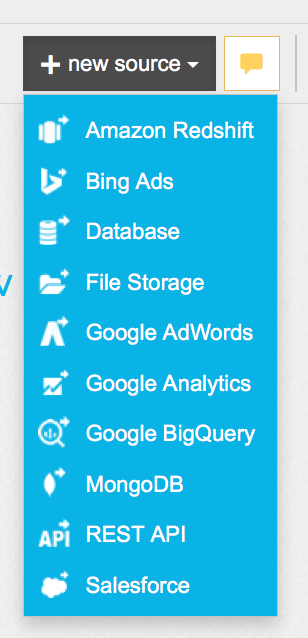
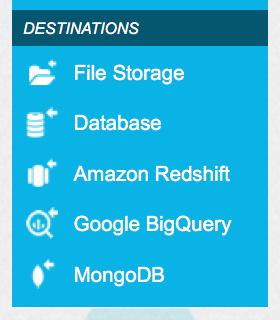
optionally perform some simple operations on them, and then choose from several destinations for your data.
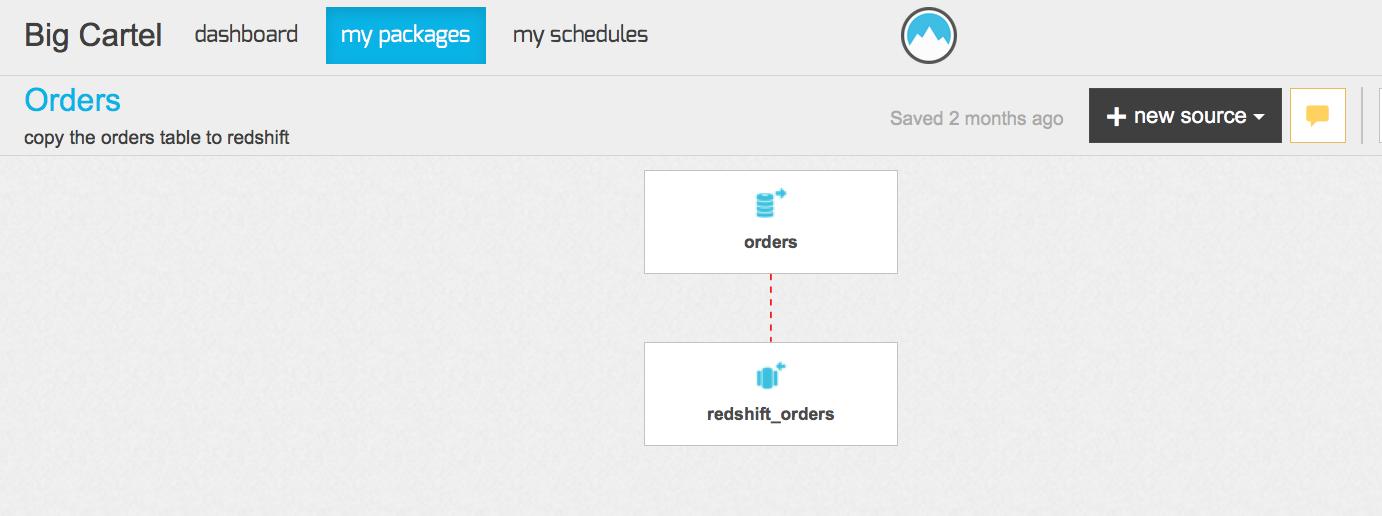
Most of my packages look like this:
Once you have some packages, you can schedule them:

and you can see the history of your package runs or manually run one from your dashboard
This is all pretty straightforward, but it adds up to a LOT of infrastructure we don't have to own ourselves. Xplenty gives us a shared place to define the jobs and schedule them to run. It handles spinning up a cluster on AWS to run the jobs - right now we only need a small one, but if that changes, it's very easy to ask for more nodes. They have really great customer support - chat in app that goes to email if you wander off. I get such friendly and helpful replies that I probably pester them _more_ because I know I'll actually get a real response. We have Xplenty set up to tie into PagerDuty, so I get emails about job fails (and if we really needed to, I could get paged.)
(Old person aside - I have owned a web-based scheduler tool before and I would really rather not have to again.)
The upsides of this managed infrastructure led me to an interesting corner case - sometimes I want to compute a number and store it regularly. Usually once a day. What's my tool to store things? Xplenty. What's my tool to compute things? Uhm, well, usually it's SQL. In this case, I had a fairly involved SQL query that I knew worked for the computation. AND I already had Xplenty sending the data it needed to Redshift. I was realllllly tempted to just put the query in a repo and then cron up the psql command to Redshift somewhere.
But:
- where would I run it?
- what would watch cron to let me know it successfully ran?
- what makes sure that box continues to have access to Redshift?
- what if someone else needs to see all the things running on Redshift?
- how would someone else find it to update it?
Running it via Xplenty answers all of these in a consistent way. It felt very weird to build a package this complex
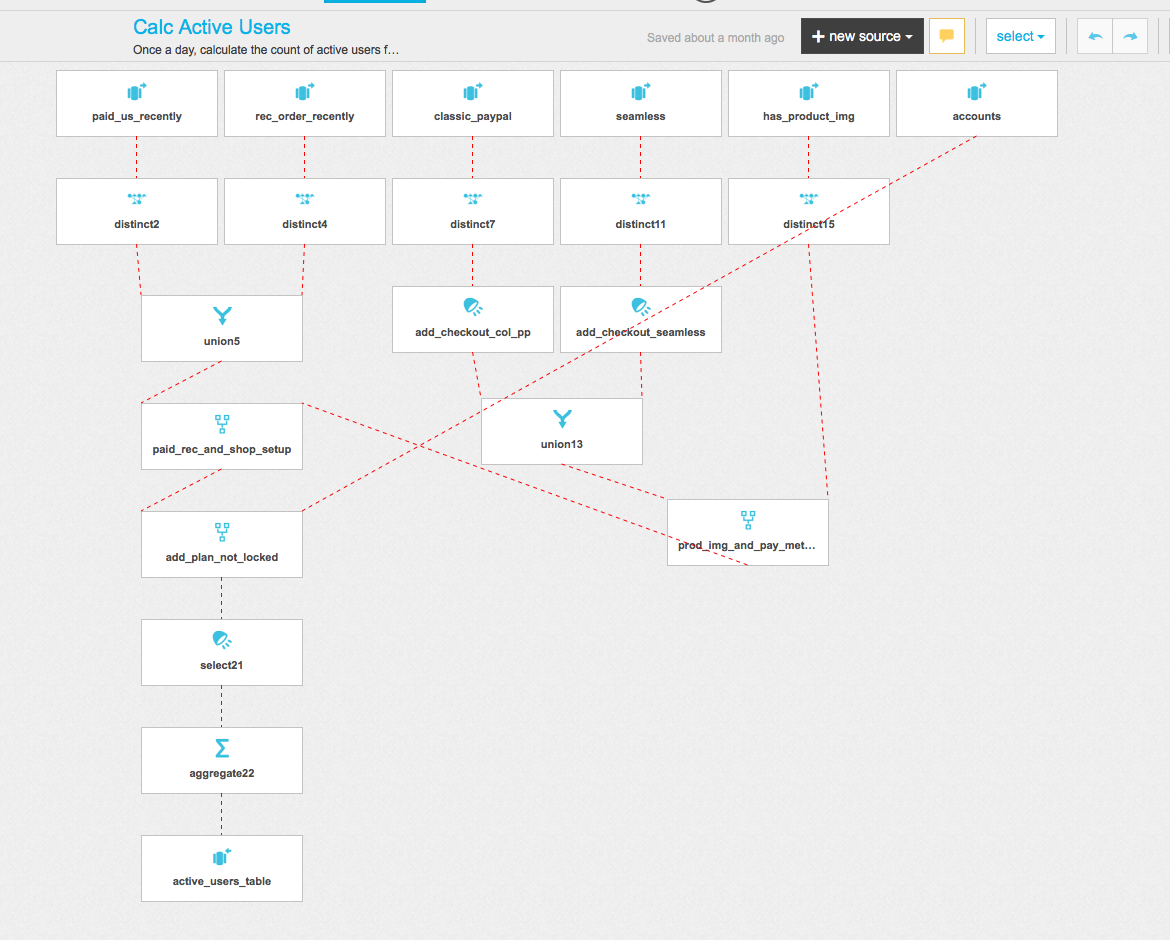
but it was worth it to have all of my data transfer run in a consistent and easy-to-find way. What would you have done? Why?
What are some other tools in this particular niche: moving data out of your backend transactional databases to a data warehouse?